RNN リカレントニューラルネットワークについての蘊蓄
NETtalk
系列情報処理を扱った初期のニューラルネットワーク例として NETTalk が挙げられます。 NETTalk1 は文字を音読するネットワークです。下図のような構成になっています。 下図のようにアルファベット 7 文字を入力して,空白はアンダーラインで表現されています,中央の文字の発音を学習する 3 層のニューラルネットワークです。NETTalk は 7 文字幅の窓を移動させながら 逐次中央の文字の発音を学習しました。たとえば /I ate the apple/ という文章では “the” を “ザ” ではなく “ジ” と発音することになります。
印刷単語の読字過程のニューラルネットワークモデルである SM892, PMSP963 で用いられた発音表現は ARPABET の亜種です。Python では nltk ライブラリを使うと ARPABET の発音を得ることができます(ARPABET のデモ![]() )。
)。
 </br>
Sejnowski (1986) Fig. 2
</br>
Sejnowski (1986) Fig. 2
単純再帰型ニューラルネットワーク
NETTalk を先がけとして 単純再帰型ニューラルネットワーク Simple Recurrent Neural networks (SRN) が提案されました。 発案者の名前で Jordan ネット4,Elman ネット5 と呼ばれます。
Jordan ネットも Elman ネットも上位層からの 帰還信号 を持ちます。これを フィードバック結合 と呼び,位置時刻前の状態が次の時刻に使われます。Jordan ネットでは一時刻前の出力層の情報が用いられます(下図)。

図:マイケル・ジョーダン発案ジョーダンネット [@1986Jordan]

図:ジェフ・エルマン発案のエルマンネット[@lman1990],[@Elman1993]
どちらも一時刻前の状態を短期記憶として保持して利用するのですが,実際の学習では一時刻前の状態をコピーして保存しておくだけで,実際の学習では通常の 誤差逆伝播法 すなわちバックプロパゲーション法が用いられます。上 2 つの図に示したとおり U と W とは共に中間層への結合係数であり,V は中間層から出力層への結合係数です。Z=I と書き点線で描かれている矢印はコピーするだけですので学習は起こりません。このように考えれば SRN は 3 層のニューラルネットワークであることが分かります。
SRN はこのような単純な構造にも関わらず チューリング完全 であろうと言われてきました。 すなわちコンピュータで計算可能な問題はすべて計算できるくらい強力な計算機だという意味です。
- Jordan ネットは出力層の情報を用いるため 運動制御 に
- Elan ネットは内部状態を利用するため 言語処理 に
それぞれ用いられます。従って 失行 aparxia (no matter what kind of apraxia such as ‘ideomotor’ or ‘conceptual’),行為障害 のモデルを考える場合 Jordan ネットは考慮すべき選択肢の候補の一つとなるでしょう。
リカレントニューラルネットワークの時間展開
一時刻前の状態を保持して利用する SRN は下図左のように描くことができます。同時に時間発展を考慮すれば下図右のように描くことも可能です。
 </br>
Time unfoldings of recurrent neural networks
</br>
Time unfoldings of recurrent neural networks
上図右を頭部を 90 度右に傾けて眺めてください。あるいは同義ですが上図右を反時計回りに 90 度回転させたメンタルローテーションを想像してください。このことから “SRN とは時間方向に展開したディープラーニングである” ことが分かります。
エルマンネットによる言語モデル
下図に エルマン が用いたネットワークモデルを示しました。図中の数字はニューロンの数を表します。入力層と出力層のニューロン数 26 とは,もちいた語彙数が 26 であったことを表します。

from [@Elman1991startingsmall]
エルマンは,系列予測課題によって次の単語を予想することを繰り返し学習させた結果,文法構造がネットワークの結合係数として学習されることを示しました。Elman ネットによって,埋め込み文の処理,時制の一致,性や数の一致,長距離依存などを正しく予測できることが示されました(Elman, 1990, 1991, 1993)。
- S $\rightarrow$ NP VP “.”
- NP $\rightarrow$ PropN | N | N RC
- VP $\rightarrow$ V (NP)
- RC $\rightarrow$ who NP VP | who VP (NP)
- N $\rightarrow$ boy | girl | cat | dog | boys | girls | cats | dogs
- PropN $\rightarrow$ John | Mary |
- V $\rightarrow$ chase | feed | see | hear | walk | live | chases | feeds | seeds | hears | walks | lives
これらの規則にはさらに 2 つの制約があります。
- N と V の数が一致していなければならない
- 目的語を取る動詞に制限がある。例えばhit, feed は直接目的語が必ず必要であり,see とhear は目的語をとってもとらなくても良い。walk とlive では目的語は不要である。
文章は 23 個の項目から構成され,8 個の名詞と 12 個の動詞,関係代名詞 who,及び文の終端を表すピリオドです。この文法規則から生成される文 S は,名詞句 NP と動詞句 VP と最後にピリオドから成り立っている。 名詞句 NP は固有名詞 PropN か名詞 N か名詞に関係節 RC が付加したものの何れかとなります。 動詞句 VP は動詞 V と名詞句 NP から構成されるが名詞句が付加されるか否かは動詞の種類によって定まる。 関係節 RC は関係代名詞 who で始まり,名詞句 NP と動詞句 VP か,もしくは動詞句だけのどちらかかが続く,というものです。
下図に訓練後の中間層の状態を主成分分析にかけた結果を示しました。”boy chases boy”, “boy sees boy”, および “boy walks” という文を逐次入力した場合の遷移を示しています。 同じ文型の文章は同じような状態遷移を辿ることが分かります。
 </br>
</br>
下図は文 “boy chases boy who chases boy” を入力した場合の遷移図です。この文章には単語 “boy” が 3 度出てきます。それぞれが異なるけれど,他の単語とは異なる位置に附置されていることがわかります。 同様に ‘chases” が 2 度出てきますが,やはり同じような位置で,かつ,別の単語とは異なる位置に附置されています。</br>

同様にして “boy who chases boy chases boy” (男の子を追いかける男の子が男の子を追いかける) の状態遷移図を下図に示しました。</br>
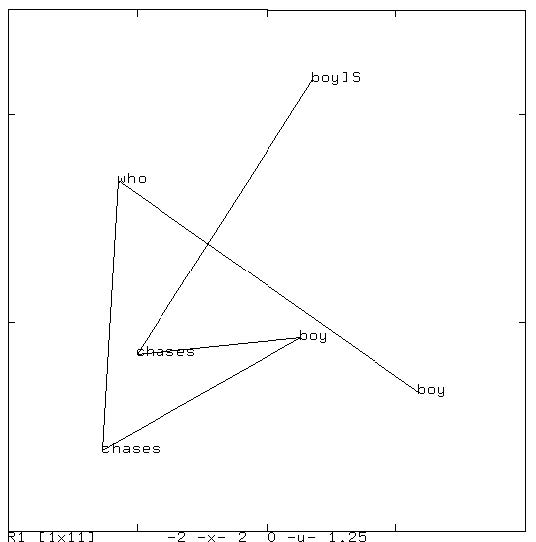
さらに複雑な文章例 “boy chases boy who chases boy who chases boy” の状態遷移図を下図に島します。</br>
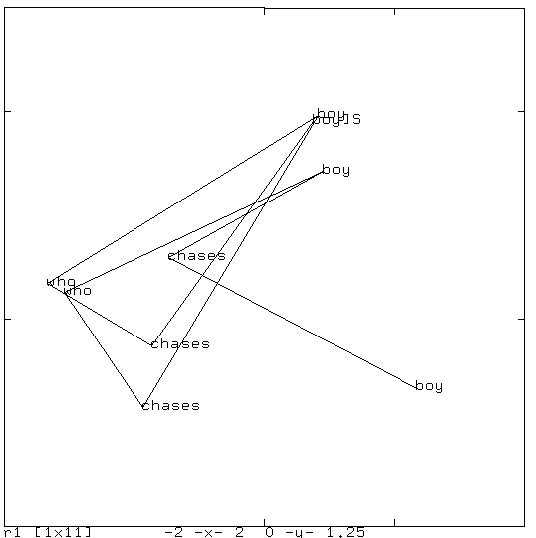
Elman ネットが構文,文法処理ができるということは上図のような中間層での状態遷移で同じ単語が 異なる文位置で異なる文法的役割を担っている場合に,微妙に異なる表象を,図に即してで言えば, 同じ単語では,同じような場所を占めるが,その文法的役割によって異なる位置を占めることが 示唆されます。このことから中間層の状態は異なる文章の表現を異なる位置として表現していることが考えられ, 後述する 単語の意味 や 自動翻訳 などに使われることに繋がります(浅川の主観半分以上)
“Seq2sep” 翻訳モデル
上記の中間層の状態を素直に応用すると 機械翻訳 や 対話 のモデルになります。
下図は初期の翻訳モデルである “seq2seq” の概念図を示しました。
“<eos>” は文末 end of sentence を表します。中央の “<eos>” の前がソース言語
であり,中央の “<eos>” の後はターゲット言語の言語モデルである SRN の中間層への
入力として用います。
注意すべきは,ソース言語の文終了時の中間層状態のみをターゲット言語の最初の中間層 の入力に用いることであり,それ以外の時刻ではソース言語とターゲット言語は関係が ないことです。逆に言えば最終時刻の中間層状態がソース文の情報全てを含んでいると みなすことです。この点を改善することを目指すことが 2014 年以降盛んに行われてきました。 顕著な例が後述する 双方向 RNN, LSTM を採用したり,注意 機構を導入することでした。

From [@2014Sutskever_Sequence_to_Sequence]
多様な RNN とその万能性
双方向 RNN や LSTM を紹介する前に,カルパシーのブログ[^karpathy] から下図に引用します。 下の 2 つ図ではピンク色が入力層,緑が中間層,青が出力層を示しています。
| [^karpathy]: 去年までスタンフォード大学の大学院生。現在はステラ自動車,イーロン・マスクが社長,の AI 部長さんです。図は彼のブログから引用です。蛇足ですがブログのタイトルが unreasonable effectiveness of RNN です。過去の偉大な論文 Wiegner (1960), Hamming (1967), Halevy (2009) からの |
mathematics | data]” $\ldots$ www |
 >
>RNN variations from <http://karpathy.github.io/2015/05/21/rnn-effectiveness/>
- 上図最左は通常の多層ニューラルネットワークで画像認識,分類,識別問題に用いられます。
- 上図左から 2 つ目は,画像からの文章生成
- 上図中央,左から 3 つ目は,極性分析,文章のレビュー,星の数推定
- 上図右から 2 つ目は翻訳や文章生成
- 上図最右はビデオ分析,ビデオ脚注付け
などに用いられます。これまで理解を促進する目的で中間層をただ一層として描いてきました。 ですがが中間層は多層化されていることの方が多いこと,中間層各層のニューロン数は 1024 程度まで用いられていることには注意してください。
数は各層のニューロン数が 4 つである場合の数値例を示しています。入力層では ワンホット 表現6
 ></br>
RNN variations from <http://karpathy.github.io/2015/05/21/rnn-effectiveness/>
></br>
RNN variations from <http://karpathy.github.io/2015/05/21/rnn-effectiveness/>
[@1991Siegelmann_RNN_universal] said Turing completeness of RNN.
双方向 RNN BiRNN
RNN を改善するモデルとして 2 つ紹介します。一つは 双方向 RNN bidirectional RNN (BiRNN) で Shuster[^shuster],別は LSTM です。ここでは BiRNN を扱います。下図に BiRNN の概念図を示しました。 BiRNN は RNN が 2 つ逆方向に走っていて互いに交わることはありません。 この意味では時間を逆向きに考えるだけなのでプログラム上の難しさは有りません。 時刻 $t$ での出力 $y(t)$ を得るためには,$[0\ldots,t-1]$ までの順方法 RNN と $[T,\ldots,t+1]$ までの逆方法 RNN を用いて予測します。 逆方法 RNN は未来から過去を予測することを意味します。物理的因果律に違反することになるので 気持ち悪いとも言えます。ですが英単語 “the” の発音は後続する名詞を知っていれば発音を 予測することは容易です。同様にフランス語の定冠詞を “ラ” にするか “ル” にするかは 後続する名詞の性が分かっていれば容易です。このように自然言語処理では BiRNN を使うと 精度向上が期待される場合頻用されます。ここには神経心理学的な意味づけと工学的価値との齟齬,乖離が あります。
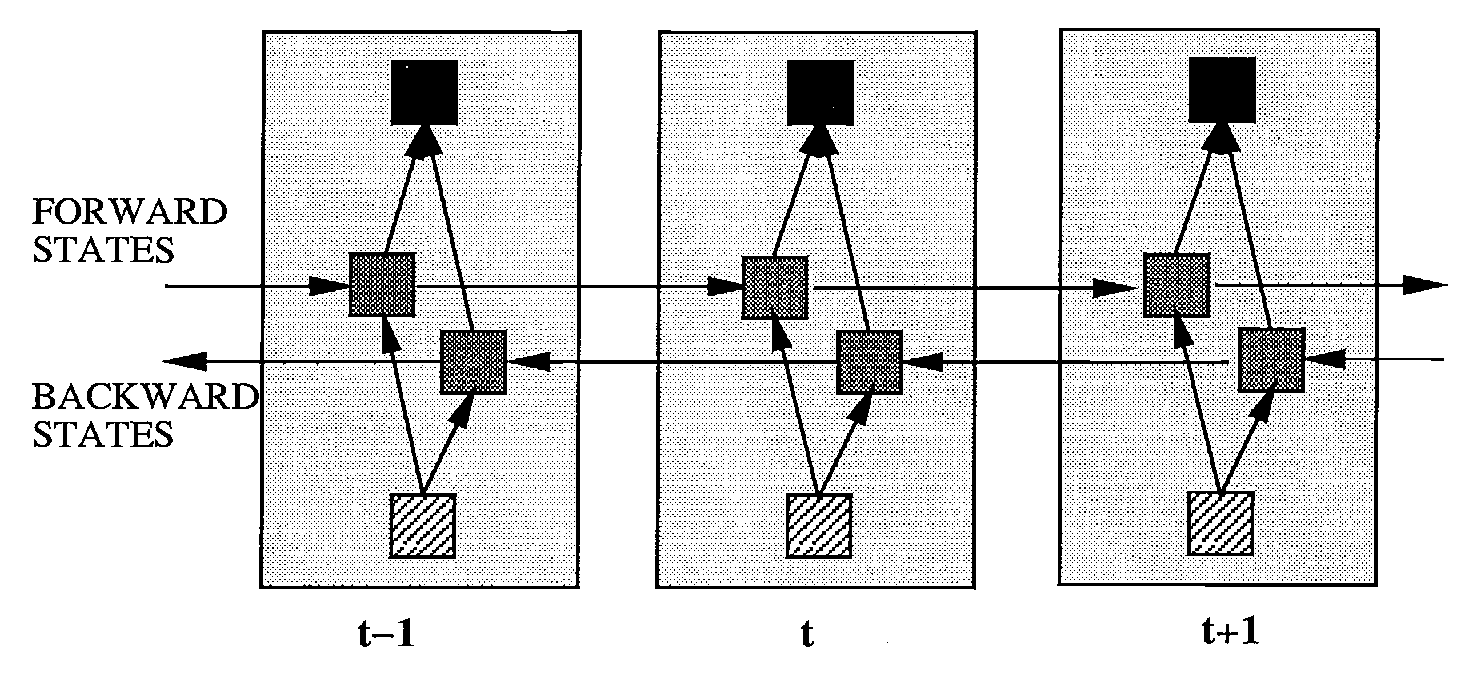 </br>
</br>
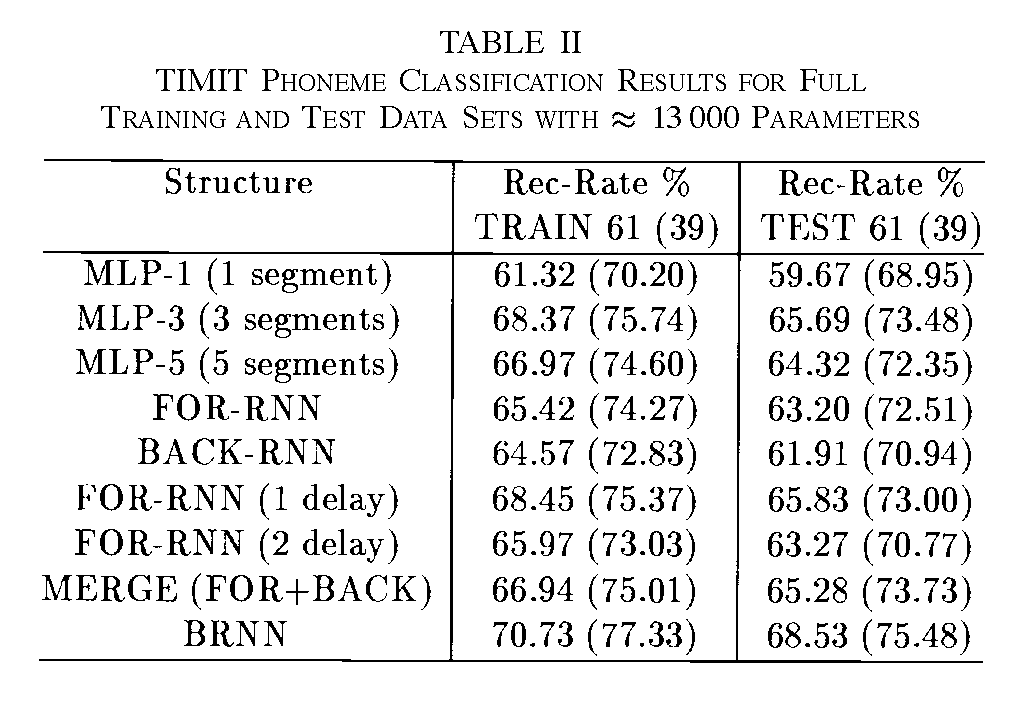
下図に BiRNN の音声認識データセットを用いた性能比較を示しました。図中では “BiRNN” が “BRNN” と表記されています。
 </br>
</br>
Shuster (1997) Fig.1, Tab. 2
長距離依存
上では RNN は時間方向でのディープラーニング(深層学習)であると説明しました。 ですが過去の情報を用いるために,一時刻前,すなわち直前の情報ではなく過去のある時点での情報を保持しておいて使いたい場合がありまs。英語の関係代名詞節を名詞の修飾に用いるような 中央埋め込み文 では, 主語と動詞との間で時制の一致が必要ですが,主語の後に関係代名詞節が埋め込まれると,主語の時制や数を 覚えておく必要が生じます。
文 “boy that girls chase plays the guitar” では関係代名詞節内の主語 “girls” が複数形です。 この複数形 “girls” に引きづられて動詞 “plays” を “play” としては正しい文法になりません。
このように過去の情報を覚えておく必要があります。これを 長距離依存 long term dependency と言います。SRN は長距離依存解消のために学習時間が長くなるという問題点があります。 これは中間層の内容が時々刻々変化し続けるため,特定の内容を保持することが困難になると考えられます。 この長距離依存解消が難しいという短所は,記憶内容を保持しておく別の場所,短期記憶バッファを用意するなどの解消方法も存在します。一方,短期記憶を保持する機構をリカレントニューラルネットワーク内に組み込むという考え方もあります。後者の考え方を実現する方法として次に紹介する長=短期記憶モデルがあります。
 </br>
Schematic description of a long term dependency
</br>
Schematic description of a long term dependency
長=短期記憶
長=短期記憶 (Long Short-Term Memory: LSTM, henceforth) はシュミットフーバー (Shumithuber, J.) 一派により提案された長距離依存解消のためのニューラルネットワークモデルです。 長距離依存を解消するためには,ある内容を保持し続けて必要に応じてその内容を表出する必要があります。 このことを実現するために,ニューロンへの入力に門 (gate) を置くことが提案されました。 下図に長=短期記憶モデルの概念図を示しました。

LSTM from [@2016Asakawa_AIdict]
上図の LSTM は一つのニューロンに該当します。このニューロンには 3 つのゲート(gate, 門) が付いています。 3 つのゲートは以下の名前で呼ばれます。
- 入力ゲート input gate
- 出力ゲート output gate
- 忘却ゲート forget gate
各ゲートの位置を上図で確認してください。入力ゲートと出力ゲートが閉じていれば,セルの内容(これまでは中間層の状態と呼んできました)が保持されることになります。 出力ゲートが開いている場合には,セル内容が出力されます。一方出力ゲートが閉じていればそのセル内容は出力されません。このように入力ゲートと出力ゲートはセル内容の入出力に関与します。 忘却ゲートはセル内容の保持に関与します。忘却ゲートが開いていれば一時刻前のセル内容が保持されることを意味します。反対に忘却ゲートが閉じていれば一時刻前のセル内容は破棄されます。全セルの忘却ゲートが全閉ならば通常の多層ニューラルネットワークであることと同義です。すなわち記憶内容を保持しないことを意味します。SRN でフィードバック信号が存在しない場合に相当します。セルへの入力は,
- 下層からの信号,
- 上層からの信号, すなわち Jordan ネットの帰還信号
- 自分自身の内容,すなわち Elman ネットの帰還信号
が用いられます。これら入力信号が
- 入力信号そのもの
- 入力ゲートの開閉制御用信号
- 出力ゲートの開閉制御用信号
- 忘却ゲートの開閉制御用信号
という 4 種類に用いられます。従って LSTM のパラメータ数は SRN に比べて 4 倍になります。
LSTM に限らず一般のニューラルネットワークの出力には非線形関数が用いられます。代表的な非線形出力関数としては,以下のような関数が挙げられます。
- シグモイド関数7: $f(x)=\left[1+e^{-x}\right]^{-1}$
- ハイパーボリックタンジェント関数: $f(x)=\left(e^{x}-e^{-x}\right)/\left(e^{x}+e^{-x}\right)$
- 整流線形ユニット関数: $f(x)=\max\left(0,x\right)$
この中で,セルの出力関数として 2. のハイパーボリックタンジェント関数が,ゲートの出力関数にはシグモイド関数が使われます。その理由はハイパーボリックタンジェント関数の方が収束が早いこと,シグモイド関数は値域が $[0,1]$ であるためゲートの開閉に直接対応しているからです。
- Le Cun, Y. Bottou, L., Orr, G. B, Muller K-R. (1988) Efficient BackProp, in Orr, G. and Muller, K. (Eds.) Neural Networks: tricks and trade, Springer.
LSTM におけるゲートの生理学的対応物
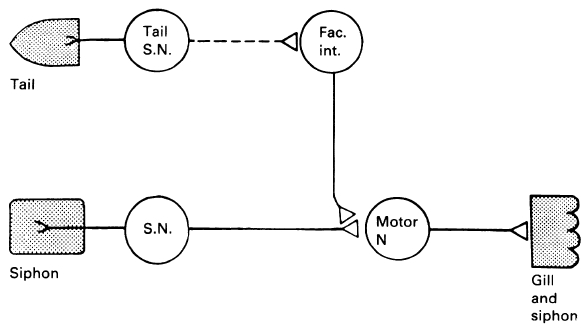
以下の画像は http://kybele.psych.cornell.edu/~edelman/Psych-2140/week-2-2.html よりの引用です。 ウミウシのエラ引っ込め反応時に,ニューロンへの入力信号ではなく,入力信号を修飾する結合 が存在します。下図参照。 <!–
 </br>
</br>
–>
 </br>
</br>
 </br>
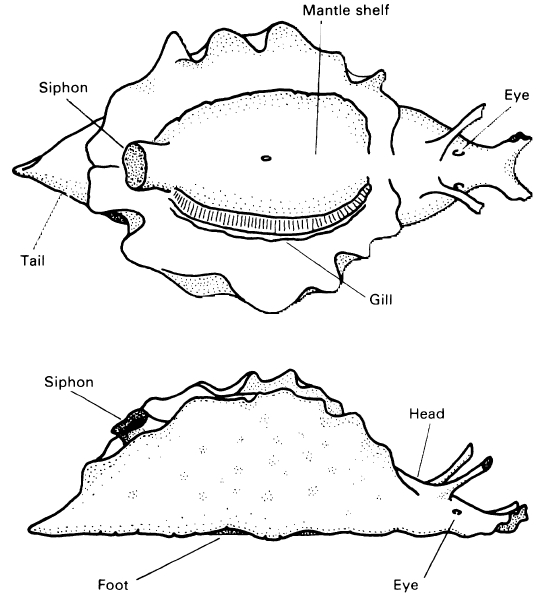
アメフラシ (Aplysia) のエラ引っ込め反応(a.k.a. 防御反応)の模式図[^seaslang]
</br>
アメフラシ (Aplysia) のエラ引っ込め反応(a.k.a. 防御反応)の模式図[^seaslang]
画像はそれぞれ http://kybele.psych.cornell.edu/~edelman/Psych-2140/shunting-inhibition.jpg
http://kybele.psych.cornell.edu/~edelman/Psych-2140/C87-fig2.25.jpg
http://kybele.psych.cornell.edu/~edelman/Psych-2140/C87-fig2.24.jpg
また古くは PDP のバイブルにもシグマパイユニット ($\sigma\pi$ units) として既述が見られます。各ユニットを掛け算 ($\pi$) してから足し算 ($\sum$) するのでこのように命名されたのでしょう。
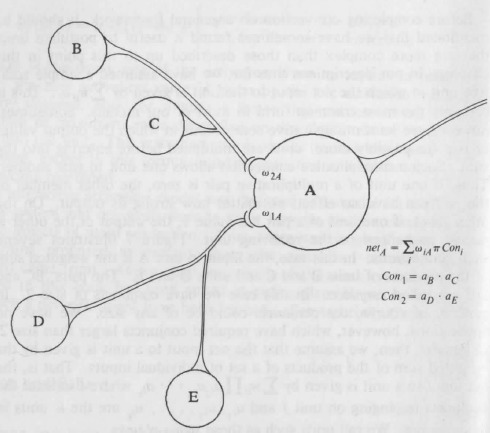
From [@PDPbook] chaper 7
画像と言語との融合へ向けて
以上で今回の特別企画の目標である画像と言語とのマルチモーダル統合へ向けての準備がほぼ出揃いました。 2014 年に提案されたニューラル画像脚注付けのモデルを下図に示します。

[@2014Vinyals_Bengio_Show_and_Tell]
画像に対して注意を付加した脚注付けモデルの出力例を下図に示します。
各画像対は右が入力画像であり,左はその入力画像の脚注付けである単語を出力している際にどこに注意しているのかを白色で表しています。
 </br>
[@2015Xu_Bengio_NIC_attention]
</br>
[@2015Xu_Bengio_NIC_attention]
-
Sejnowski, T.J. and Rosenberg, C. R. (1987) Parallel Networks that Learn to Pronounce English Text, Complex Systems 1, 145-168. ↩
-
Seidenberg, M. S. & McClelland, J. L. (1989). A distributed, developmetal model of word recognition and naming. Psychological Review, 96(4), 523–568. ↩
-
Plaut, D. C., McClelland, J. L., Seidenberg, M. S. & Patterson, K. (1996). Understanding normal and impaired word reading: Computational principles in quasi-regular domains. Psychological Review, 103, 56–115. ↩
-
Joradn, M.I. (1986) Serial Order: A Parallel Distributed Processing Approach, UCSD tech report. ↩
-
Elman, J. L. (1990)Finding structure in time, Cognitive Science, 14, 179-211. ↩
-
ベクトルの要素のうち一つだけが “1” であり他は全て “0” である疎なベクトルのこと。一つだけが “熱い” あるいは “辛い” ベクトルと呼びます。以前は one-of-$k$ 表現 (MacKay の PRML など) と呼ばれていたのですが ワンホット表現,あるいは ワンホットベクトル (おそらく命名者は Begnio 一派)と呼ばれることが多いです。ワンホットベクトルを学習させると時間がかかるという計算上の弱点が生じます。典型的な誤差逆伝播法による学習では,下位層の入力値に結合係数を掛けた値で結合係数を更新します。従って,下位層の値のほとんどが “0” であるワンホットベクトルは学習効率が落ちることになります。そこで Elman はワンホットベクトルを実数値を持つ多次元ベクトルに変換してから用いることを行いました。上のエルマンネットによる文法学習において,ニューロン数 10 の単語埋め込み層と書かれた層がこれに該当します。単語埋め込み層を用いることで学習効率が改善し,後に示す word2vec などの 分散ベクトルモデル へと発展します。 ↩
-
1980 年代に用いられたシグモイド関数が用いられることはほとんどなくなりました。理由は収束が遅いからです[@1999LeCun] ↩