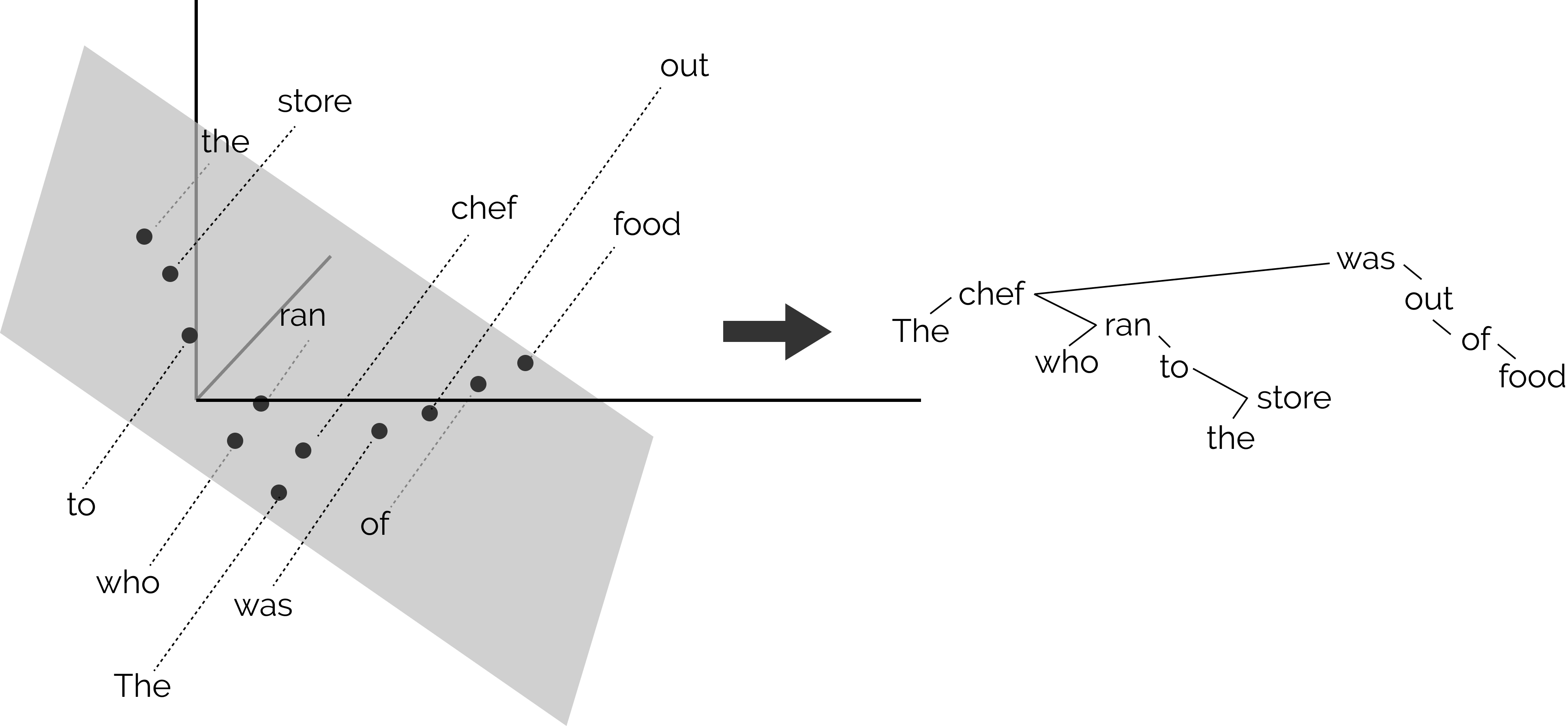
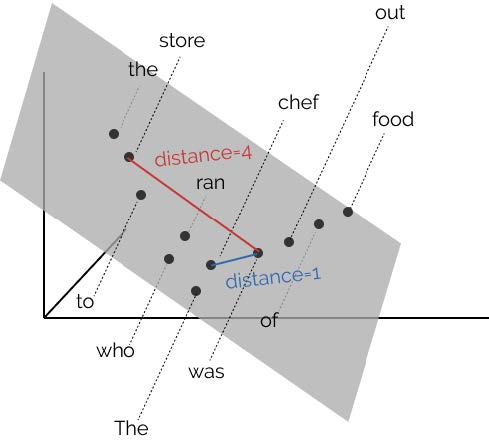
Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. 2015. “Neural Machine Translation by Jointly Learning to Align and Translate.” In Proceedings in the International Conference on Learning Representations (ICLR), edited by Yoshua Bengio and Yann LeCun. San Diego, CA, USA. http://arxiv.org/abs/1409.0473.
Chen, Yunpeng, Yannis Kalantidis, Jianshu Li, Shuicheng Yan, and Jiashi Feng. 2018. “\(A^2\)-Nets: Double Attention Networks.” In Advances in Neural Information Processing Systems 31, edited by S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, 352–61. Curran Associates, Inc. http://papers.nips.cc/paper/7318-a2-nets-double-attention-networks.pdf.
Cordonnier, Jean-Baptiste, Andreas Loukas, and Martin Jaggi. 2020. “ON the Relationship Between Self-Attention and Convolutional Layers.” ArXiv Preprint [cs.LG] (1911.035842). https://arxiv.org/1911.03584/.
Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. “BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding.” arXiv Preprint.
Elman, Jeffrey L. 1990. “Finding Structure in Time.” Cognitive Science 14: 179–211.
Gers, Fleix A., Jürgen Schmidhuber, and Fred Cummins. 1999. “Learning to Forget: Continual Prediction with LSTM.” In Artificial Neural Networks ICANN 99. Ninth International Conference on, 2:850–55. Edinburgh, Scotland.
Greff, Klaus, Rupesh Kumar Srivastava, Jan Koutník, Bas R. Steunebrink, and Jürgen Schmidhuber. 2015. “LSTM: A Search Space Odyssey.” ArXiv:1503.04069.
Hewitt, John, and Christopher D. Manning. 2019. “A Structural Probe for Finding Syntax in Word Representations.” In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 4129–38. Minneapolis, Minnesota: Association for Computational Linguistics. https://doi.org/10.18653/v1/N19-1419.
Hochreiter, Sepp, and Jürgen Schmidhuber. 1997. “Long Short-Term Memory.” Neural Computation 9: 1735–80.
Jones, Karen Spärck. 1972. “A Statistical Interpretation of Term Specificity and Its Application in Retrieval.” Journal of Documentation 28 (1): 11–21.
Kim, Junho, Minjae Kim, Hyeonwoo Kang, and Kwanghee Lee. 2019. “U-GAT-IT: Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation.” ArXiv Preprint [cs.CV] (1907.10830).
Lample, Guillaume, and Alexis Conneau. 2019. “Cross-Lingual Language Model Pretraining.” ArXiv Preprint 1901.07291v1 [cs.CL].
Liu, Xiaodong, Pengcheng He, Weizhu Chen, and Jianfeng Gao. 2019. “Multi-Task Deep Neural Networks for Natural Language Understanding.” In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 4487–96. Florence, Italy: Association for Computational Linguistics.
Liu, Yinhan, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. “RoBERTa: A Robustly Optimized Bert Pretraining Approach.” ArXiv Preprint.
Luong, Minh-Thang, Hieu Pham, and Christopher D. Manning. 2015. “Effective Approaches to Attention-Based Neural Machine Translation.” ArXiv Preprint cs.CL: 1508.04025.
Manning, Christopher D., and Hinrich Schuütze. 1999. Foundations of Statistical Natural Language Processing. Cambridge, MA, USA: MIT press.
Mikolov, Tomaś, Stefan Kombrink, Lukaś Burget, Jan “Honza" Černocký, and Sanjeev Khudanpur. 2011. “Extensions of Recurrent Neural Network Language Model.” In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Prague, Czech Republic.
Mikolov, Tomáš, Martin Karafiát, Lukáš Burget, Jan “Honza” Černocký, and Sanjeev Khudanpur. 2010. “Recurrent Neural Network Based Language Model.” In Proceedings of INTERSPEECH2010, edited by Takao Kobayashi, Keiichi Hirose, and Satoshi Nakamura, 1045–8. Makuhari, JAPAN.
Mishra, Nikhil, Mostafa Rohaninejad, Xi Chen, and Pieter Abbeel. 2018. “A Simple Neural Attentive Meta-Learner.” ArXiv Preprint [cs.AI] (1707.03141).
Mnih, Volodymyr, Nicolas Heess, Alex Graves, and Koray Kavukcuoglu. 2014. “Recurrent Models of Visual Attention.” In Advances in Neural Information Processing Systems 27, edited by Zoubin Ghahramani, Max Welling, C. Cortes, N. D. Lawrence, and K. Q. Weinberger, 2204–12. Curran Associates, Inc. http://papers.nips.cc/paper/5542-recurrent-models-of-visual-attention.pdf.
Ramachandran, Prajit, Niki Parmar, Ashish Vaswani, Irwan Bello, Anselm Levskaya, and Jonathon Shlens. 2019. “Stand-Alone Self-Attention in Vision Models.” ArXiv Preprint [cs.CV] (1906.05909). https://arxiv.org/1906.059009/.
Sanh, Victor, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2020. “DistilBERT, a Distilled Version of Bert: Smaller, Faster, Cheaper and Lighter.” ArXiv Preprint. https://arXiv.org/1910.01108.
Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. 2014. “Sequence to Sequence Learning with Neural Networks.” In Advances in Neural Information Processing Systems (NIPS), edited by Zoubin Ghahramani, M. Welling, C. Cortes, N. D. Lawrence, and K. Q. Weinberger, 27:3104–12. Montreal, BC, Canada. http://arxiv.org/abs/1409.3215v3.
Wang, Fei, Mengqing Jiang, Chen Qian, Shuo Yang, and Cheng Li. 2017. “Residual Attention Network for Image Classification.” In Proceedings of International Conference of Computer Vision (ICCV), IEEE International Conference. Venice, Italy.
Wang, Xiaolong, Ross Girshick, Abhinav Gupta, and Kaiming He. 2018. “Non-Local Neural Networks.” ArXiv Preprint [cs.CV]. https://arxiv.org/1711.07971.
Xu, Kelvin, Jimmy Lei Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhutdinov, Richard S. Zemel, and Yoshua Bengio. 2015. “Show, Attend and Tell: Neural Image Caption Generation with Visual Attention.” ArXiv:1502.03044.
Zhang, Han, Ian Goodfellow, Dimitris Metaxas, and Augustus Odena. 2019. “Self-Attention Generative Adversarial Networks.” ArXiv Preprint [stat.ML] (1805.08318).


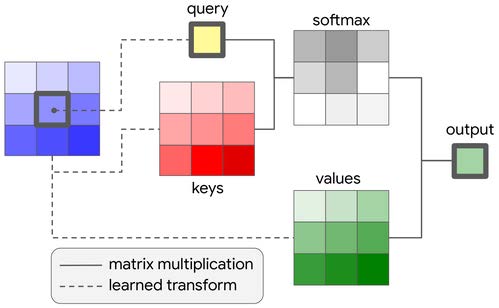
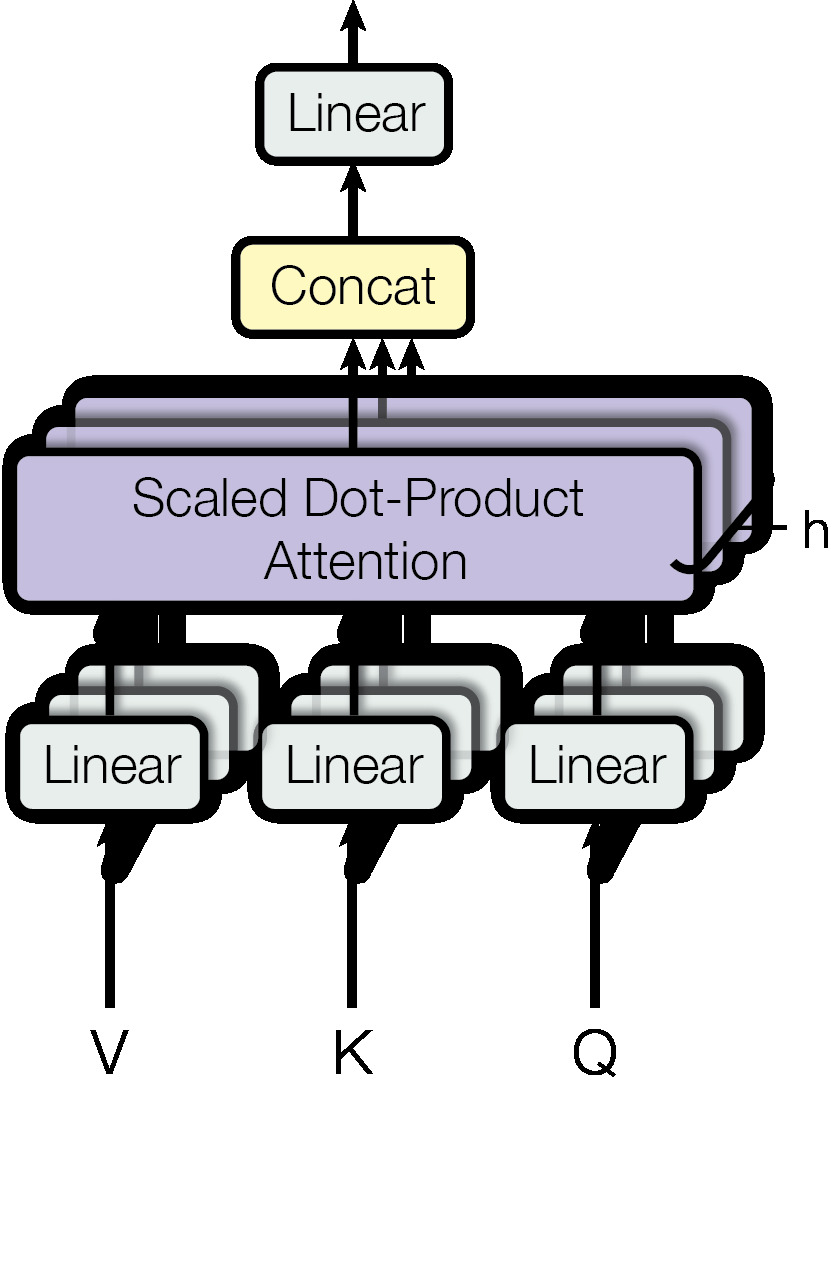








 Attention for neural image captioning
Attention for neural image captioning